Life is a paradox. It is both complex and simple to the core. Its complexity comes from the various networks and systems we are part of; from the simplest family networks to the very complex nervous system that allows me to align (or dis-align) my thinking process to write this post, we are reminded always that we are part of something so well-thought and beautifully complex. But amazingly, in the midst of all the complexities of life, our ideas, thoughts, and even our nature tends to intersect and maybe collapse at a certain singularity.
The harmony of simplicity and complexity allows us to realize that life at times might be a roller coaster ride, but upon changing the reference point (or changing the axes), we can transform something so chaotic into something so simple. One example here is getting the area of a highly irregular figure such as the map of Quezon City. Using the analytic equations by dividing it into rectangles, squares, circles, triangles, and so, we can lessen the complexity in solving for the area using the computational power of computers and a certain approximation method. Here, we used Scilab and ImageJ to approximate the area and length of known location and figure areas.
Initially, three basic figures namely, a
Circle, Square, and a
Triangle was made using the Paint tool of Microsoft as shown in Fig. 1 below.
 |
Figure 1. Three synthetic monochromatic bitmap images (ordered from left to right), a circle,
a square, and a triangle, which were created using Microsoft Paint.
|
The three were saved as monochromatic bitmap (.bmp) images. The area of the images were obtained through three different methods. The first is through the (1)
analytic equation (theoretical area) method. This can be obtained by getting the length through pixel counting (see Activity 2 for more details), and the area through the analytic equation of the known figure. Another method is called (2)
pixel counting. Here, we obtain the area by counting the number of white pixels of the figure. Lastly, we introduce the approximation method of (3)
Green's Theorem. This method uses the edges and the center of the figure to obtain an approximate area of the image through Green's Theorem given by the equation:

In this activity, we use the discrete form (discrete pixels) of the Green's Theorem given by:

.
where A is the approximated area, Nb is the number of pixels in the edges of the image, and the collection of points in the image is given by (x,y).
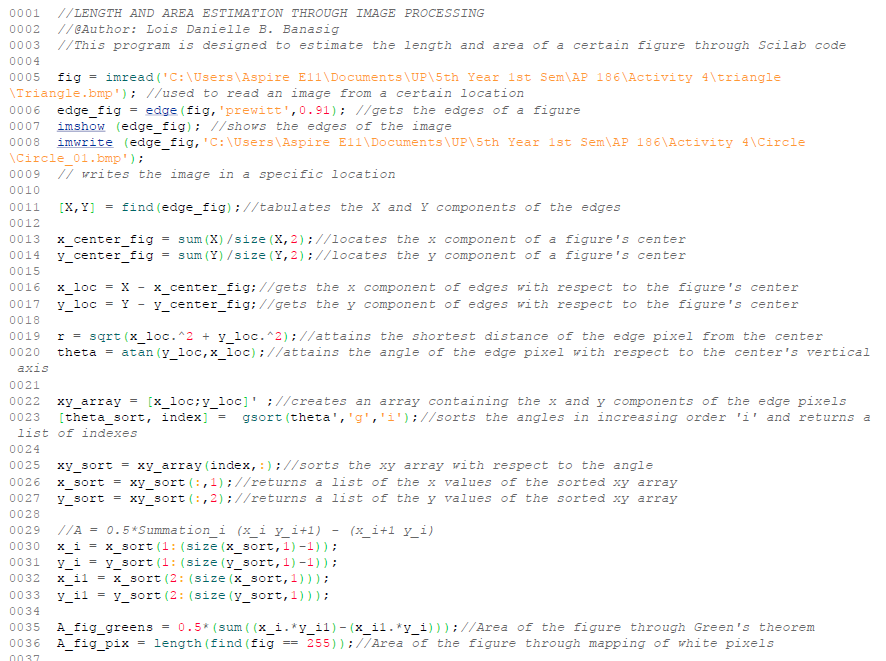
The Scilab code, as seen in the Fig. 2 below, was used to obtain the corresponding areas with varying edge detection methods, namely, Sobel, Prewitt, Canny, Log, and FFT Derivation methods.
 |
| Figure 2. The Scilab code for obtaining the approximate area of a circle, square, and triangle through pixel counting method and Green's theorem with 5 different edge detection methods (Sobel, Prewitt, Canny, Log, and FFT Derivation). |
For the area approximation methods, the pixel counting method was found to be highly reliable for both the areas of the circle and the square with corresponding percent errors with the analytical area of only 0.0391 and 0.0000 respectively. The said method was found out to have a higher percent error of 0.3577 for the triangular image which can be accounted for the graphical errors observed in Fig. 3 upon zooming-in the triangle.
 |
| Figure 3. Zoomed-in image of the triangle showing the non-cohesive behavior of the hypotenuse pixels |
It was observed that the created image using pain had non-cohesive diagonal pixels which decreased the accuracy of the area approximation methods. Upon applying the Green's theorem with edge detection for area approximation, varying accuracies were observed for different edge detection methods. This can be physically seen upon qualitatively analyzing the obtained edges for each corresponding method as seen in Figs. 4, 5, and 6.
 |
| Figure 4. Various synthetic images created using the edge detection of Scilab for a simple circular image. The (a) original image is initially shown and different methods namely the (b) Canny, (c) FFTDeriv, (d) Log, (e) Prewitt, and (f) Sobel edge detection method. |
 |
| Figure 5. Various synthetic images created using the edge detection of Scilab for a simple square image. The (a) original image is initially shown and different methods namely the (b) Canny, (c) FFTDeriv, (d) Log, (e) Prewitt, and (f) Sobel edge detection method. |
 |
| Figure 6. Various synthetic images created using the edge detection of Scilab for a simple triangular image. The (a) original image is initially shown and different methods namely the (b) Canny, (c) FFTDeriv, (d) Log, (e) Prewitt, and (f) Sobel edge detection method. |
Out of all the detection methods, the most accurate method was the Log method (percent deviations ranging from approximately 0.1% to 0.2%) which somehow sandwiches the edge with two lines: one for the inner line, and one for the outer line. The accuracy can be noticed upon zooming in the images. Due to the low image resolution, pixels tend to be non-cohesive and do not follow the expected (theoretical figure), which in return, results to an image with higher degree of error. Sandwiching the edges with inner and outer lines tend to decrease the errors brought by the pixel's non-cohesiveness for low-resolution images by means of error cancellation. The inner line gives a lower area and the outer line gives a greater area, resulting to a final averaged area with lower errors. The Prewitt and FFTDeriv methods were found to also be highly accurate with equal percent deviations ranging from 0.15% to 0.5%. The Canny method was also accurate but with higher percent errors ranging from 0.2% to 0.85% , while the Sobel method was found to have accuracy issues with errors ranging from 3% to 94%. The tabulated area values with their corresponding percent errors can be seen in Table 1 below.
Table 1. Approximated Area values with their corresponding percent deviations from the analytic value for different area approximation and edge detection methods.
For the part 2 of the activity, the approximation methods were extended in obtaining the area of a local building in UP Diliman, the CSRC, and the area of one of the largest cities in country, Quezon City. The use of Google Maps and Windows Snipping Tool was utilized, together with the Scilab code and Paint for distance scaling and area approximation. A snip of the local building/city was initially obtained from Google Maps and the distance and area measuring tool of the said application was used to obtain the approximate area of the said building (CSRC) or city (Quezon City). Paint was then used for distance scaling as done in Activity 2 of this blog and for monochrome image conversion. The process can be seen in Figs. 7, 8, and 9, wherein the approximate area of the CSRC building was obtained with the methods introduced.
 |
| Figure 7. A snip of the CSRC building obtained from Google Maps. |
 |
| Figure 8. The obtained area and perimeter of the CSRC building using Google Maps' distance calculation function. |
Initially, the theoretical value was obtained through the area and length approximation of Google Maps wherein the edges of the building was traced and scaled by the said application. The theoretical value was observed to be 1137.55 sq. meters as seen in Fig. 8.
 |
| Figure 9. Various synthetic images created using the observed 3 most efficient edge detection methods of Scilab for the CSRC building; namely, the FFT Derivation method (top), the Log method (middle), and the Prewitt method (bottom). A certain threshold values (right panes) were introduced to get more accurate representations as compared to the representations without the introduction of the said threshold (left panes). |
The multiple area values were then obtained through the observed three most efficient edge detection methods namely, the FFT Derivation, Lod, and Prewitt methods, coupled with the algorithm of Green's Theorem in Equation 2. The pixel counting method was also used for its high area approximation efficiency, represented by the small deviation from the theoretical value. The area calculated by the pixel counting method was found to be equal to 1143.4 sq. meters which garnered a percent deviation of 0.5124% with respect to the theoretical value. Edge detection methods were found to be more accurate having lower deviations of 0.4598%, 0.4734%, and 0.4598% for the FFTDeriv, Log, and Prewitt methods respectively. Threshold values of 0.75, 0.552, and 0.91 were then applied to the same methods in similar order which produced more accurate area approximation values of 1142.7, 1142.3, and 1142.7 sq. meters having deviations equal to 0.4565%, 0.4182%, and 0.4554%, respectively. The Log method was again observed to be the most efficient area approximation method upon the application of Green's theorem. The deviations can be accounted by the errors in tracing the theoretical area of the building and the deviations resulted by the pixel scaling method used.
Similar processes were also done in determining the approximate area of Quezon City and compared with the known theoretical value of 165.3 sq. km. as seen in Figs. 10, 11, and 12. The high irregularity of the city figure resulted to a much more complex process of pixel cleaning and scaling.
 |
| Figure 10. A snip of the whole Quezon City through Google Maps |
The image was cleaned and monochromatic bitmap image was obtained through the use of Microsoft Paint as seen in Fig. 11. The approximate areas were then calculated by incorporating the Green's theorem with the selected edge detection methods as seen in Fig. 12. The pixel counting method was also found to be highly accurate with only about 6.57% deviation (area = 176.16 sq.km.) from the expected value. The application of Green's theorem with Scilab Image detection was also found to be accurate with about 6.72% (area = 176.42 sq.km.), 6.84% (area = 176.60 sq.km.), and 6.73% (area = 176.42 sq.km.) deviations for the FFTDeriv, Log, and Prewitt methods, respectively. Upon varying the threshold magnitudes, the accuracy was not that improved except for the FFT Derivation method. But as we examined the resulted synthetic image for the edges, it was found out that the accuracy was just an artifact due to the deviation from the expected image. This can be observed in Table 2 and Fig. 12. Here we suggest that the obtained image from Google Maps might have accuracy issues with the known area of Quezon City. Similarly, the scaling factor given by Google Maps might also not be that accurate when applied to larger areas.
 |
| Figure 11. Pixel cleaning and scaling for the monochromatic bitmap image of the ehole Quezon City area |
 |
| Figure 12. Varied synthetic images formed through the three most efficient edge detection methods namely, the FFT Derivation (top), Log (middle), and Prewitt (bottom) methods. Threshold values (right panes) for image detection was applied to obtain more accurate area approximations as compared to the non-threshold approximations (left panes). |
Table 2. The obtained approximate area values for the areas of the CSRC building and Quezon City with corresponding percent deviations.
For the final part of the activity, ImageJ was used to determine the approximate area of a known flat object such as a school ID. Here, a scanned personal UP Diliman ID card as seen in Fig. 13 was analyzed in ImageJ for area approximation. The scanned object was then edited and aligned through Windows 10 Photoviewer and Editor for higher contrast that will be essential for edge detection (seen in Fig. 14). The said object was then varied in image sizes and their corresponding areas were then obtained and checked with the theoretical value of 8.84 sq.cm (note that the area is not of the whole ID card but of the red box for ease of use and efficiency).
 |
| Figure 13. Scanned personal UP Diliman Identification Card |
 |
| Figure 14. Edited UP Diliman ID card for alignment, scaling, and better contrast for edge detection. The image was also varied in size to obtain the dependence of the approximated area with the image size. |
The results show that ImageJ can be a reliable tool for area and length approximation with errors varying from about 0.1% to 2%. It was also observed that the deviations are proportional to the image size as seen in Table 3. But I believe that this trend is just an artifact due to resolution and accuracy of the box tool used in ImageJ.
Table 3. UP Diliman ID card approximate areas obtained through ImageJ with varying image size percentages and corresponding percent deviations.
I would like to thank the Musni Family for my long weekend Subic trip which helped me clear off my mind and allow me to be more productive the succeeding days. I would also like to thank my Adviser Dr. Rene Batac for understanding and being patient with my sickness, coupled with the moral support and academic guidance he gives.
Lastly, I would like to rate myself a 12/10 for the very rigorous parts done in not only one segment but in all segments of this activity. The complexity of each step allowed me to appreciate more hardwork and time-management in dealing with academic, family, and extra-curricular work. God bless and see you in my next blog post!




















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}